
Abstract
We propose a new approach to vision-based dexterous grasp translation, which aims to transfer grasp intent across robotic hands with differing morphologies. Given a visual observation of a source hand grasping an object, our goal is to synthesize a functionally equivalent grasp for a target hand without requiring paired demonstrations or hand-specific simulations. We frame this problem as a stochastic transport between grasp distributions using the Schrödinger Bridge formalism. Our method learns to map between source and target latent grasp spaces via score and flow matching, conditioned on visual observations. To guide this translation, we introduce physics-informed cost functions that encode alignment in base pose, contact maps, wrench space, and manipulability. Experiments across diverse hand-object pairs demonstrate our approach generates stable, physically grounded grasps with strong generalization. This work enables semantic grasp transfer for heterogeneous manipulators and bridges vision-based grasping with probabilistic generative modeling.
Demo
Source
Baseline
Ours (Pose)
Ours (Contact)
Ours (GWH)
Ours (Jacobian)
Method
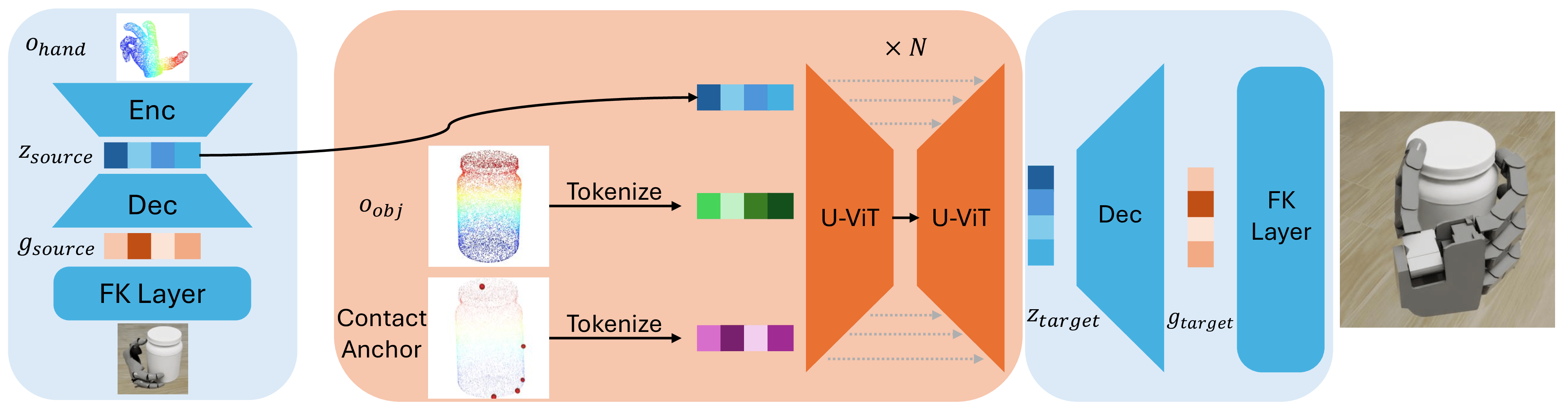
1. We encode a source hand's grasp from vision into a shared latent space using a VAE.
2. We frame grasp translation as finding the most likely path between source and target grasp distributions using a Schrödinger Bridge.
3. We guide this translation with novel, physics-informed costs (contact points, wrench similarities, manipulability) to preserve the grasp's function.
4. The model is trained without paired demonstrations or hand-specific annotations.
BibTeX
@inproceedings{
zhong2025grasp2grasp,
title={Grasp2Grasp: Vision-Based Dexterous Grasp Translation via Schr\"odinger Bridges},
author={Tao Zhong and Jonah Buchanan and Christine Allen-Blanchette},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS)},
year={2025}
}